Patterns
With Kargo being mostly unopinionated, the full range of what you can accomplish with it is vast. Sometimes, that open-endedness can be overwhelming. This section attempts to enumerate, describe, and assign names to common solutions for common use cases.
As tends to be the case with patterns, these were not invented so much as they were discovered. What we describe here is a distillation of things that have worked well for us and for other users. Importantly, the patterns described here can be tweaked to suit your needs and can even be combined with one another to address more complex use cases.
All patterns presented here will assume Argo CD as the GitOps agent.
The intent of this section is not to constrain solutions to these patterns, but to provide inspiration and guidance on how Kargo's flexibility can be leveraged creatively.
Pipeline Structure
"Pipelines" are not a formal concept in Kargo, but a term we casually use to
reference the directed acyclic graph (DAG) of resources like Warehouses and
Stages that define the flow of artifacts from their sources to their ultimate
destinations.
The patterns in this section are structural in nature. They describe common scenarios and strategies for addressing them through careful pipeline design.
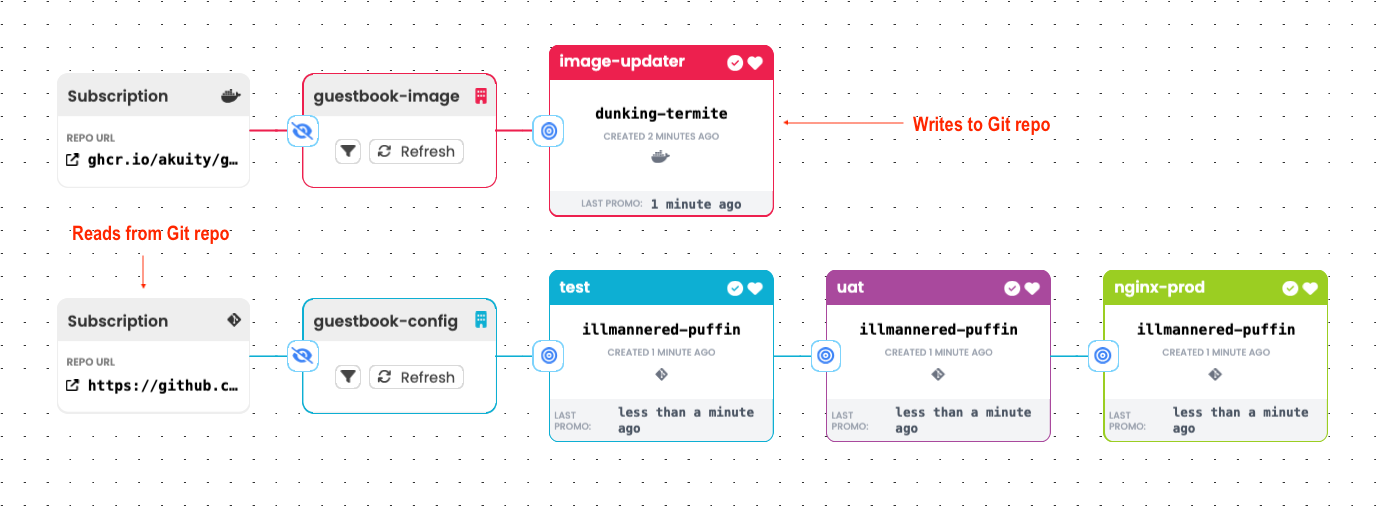
Image Updater
This simple pattern fills a similar niche to that of Argo CD Image Updater. You might consider applying this if your only concern is updating the image used by some application as new versions become available. One advantage of approaching this with Kargo is that updates are rolled out stage by stage, with a failure in a "test" stage, for instance, preventing the same update from progressing to other stages, including production.
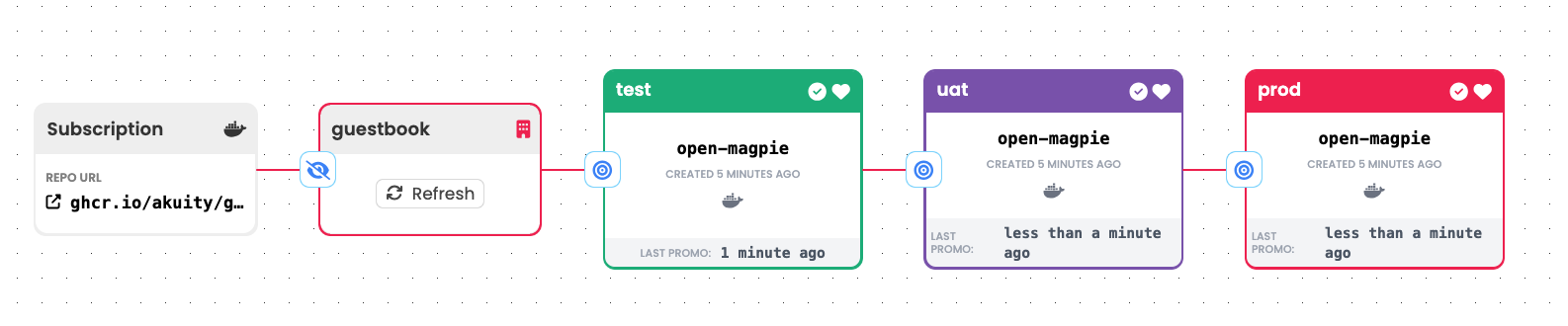
To apply this pattern:
-
Create a single
Warehousethat subscribes to an image repository with appropriate criteria so as to continuously identify the image revision you would consider to be newest. Each time it discovers a new image revision, theWarehousewill produce a newFreightresource that references it. -
Connect any number of
Stages to thisWarehouse. AsFreightoriginating from it are promoted to eachStage, they will utilize a simple promotion process that:- Updates some stage-specific configuration in a Git repository to reference the new image revision.
- Triggers an associated Argo CD
Applicationto sync with the updated configuration.
Config Updater
This simple pattern continuously monitors a Git repository for configuration changes. A distinct advantage of this pattern is that a single configuration change that is intended to be rolled out to all stages can be applied just once in the application's "base" configuration, but Kargo can still promote the change stage by stage.
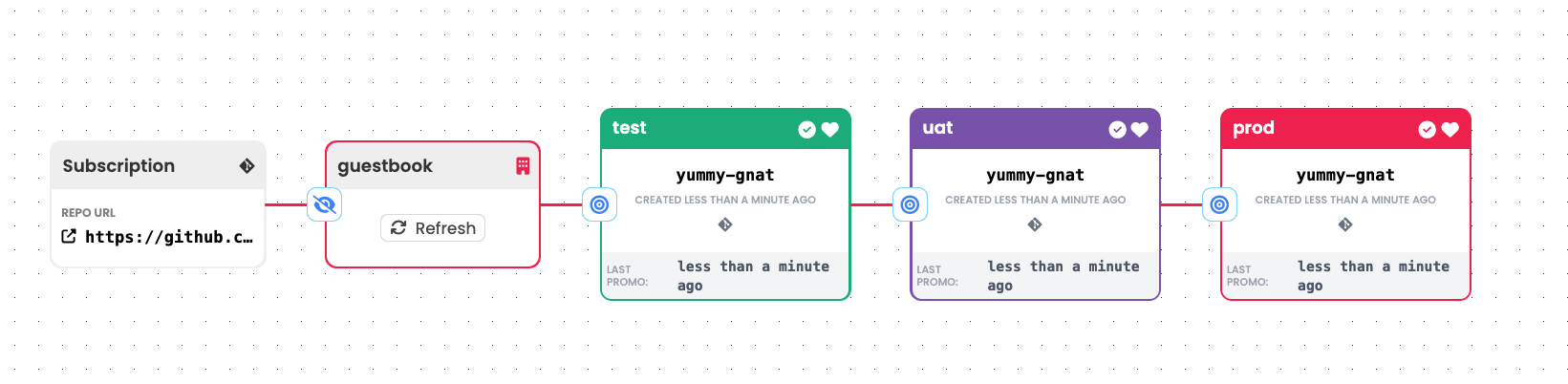
To apply this pattern:
-
Create a single
Warehousethat subscribes to a Git repository with appropriate criteria so as to continuously identify the commit containing the configuration you would consider to be newest. Typically this is simply whatever commit is at the head of yourmainbranch. Each time it discovers a new commit, theWarehousewill produce a newFreightresource that references it. -
Connect any number of
Stages to thisWarehouse. AsFreightoriginating from it are promoted to eachStage, they will utilize a simple promotion process that:- Uses a configuration management tool like Kustomize or Helm to combine the application's "base" configuration with stage-specific configuration.
- Writes the combined configuration to a Git repository.
- Triggers an associated Argo CD
Applicationto sync with the combined configuration.
The combined configuration can be written to the same Git repository that is
monitored by the Warehouse or an entirely separate repository.
If writing to the same repository, the combined configuration should be written
to a different (possibly stage-specific) branch or to a specific path within
the main branch that is ignored by the Warehouse so as not to
created a "feedback loop."
This is discussed in greater details in the Storage Options section.
This pattern can still update the image used by an application, but it treats such a change as it would any other configuration change. i.e. It does not occur automatically as in the Image Updater pattern, but any user-initiated update of application configuration to reference a new image revision will be rolled out in the same way as any other configuration change.
Common Case
The common case combines the qualities of the Image Updater and Config Updater patterns.
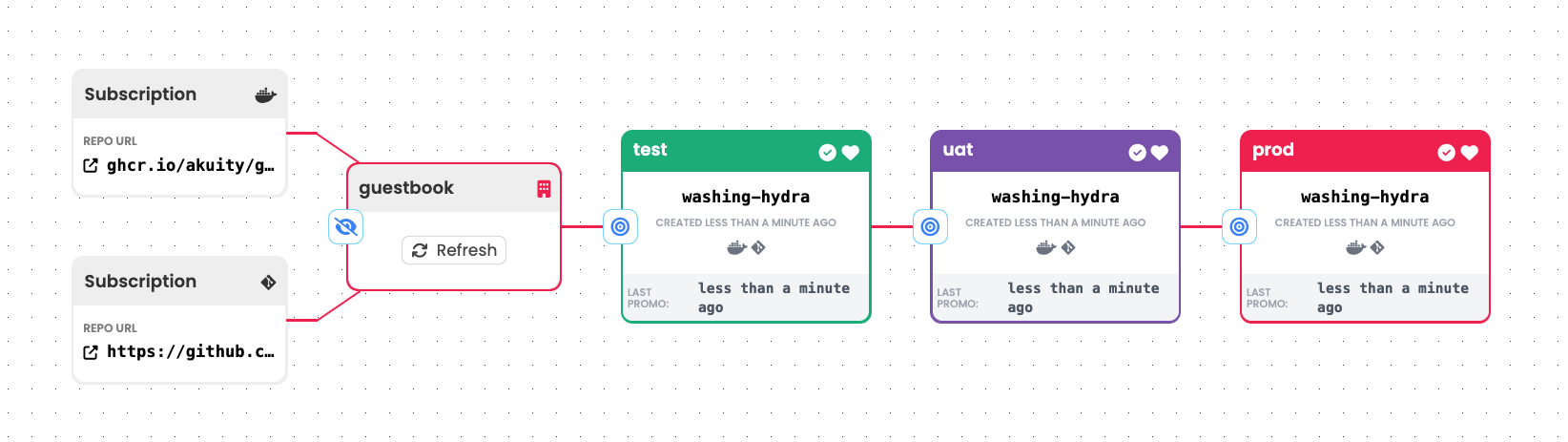
To apply this pattern:
-
Create a single
Warehousethat subscribes to an image repository and a Git repository with appropriate criteria so as to continuously identify the image revision and commit you would consider to be newest. Each time it discovers a new image revision, a new commit, or both, theWarehousewill produce a newFreightresource referencing both an image revision and a commit. Being referenced by a singleFreightresource, the two artifacts will be promoted from stage to stage together as a unit. -
Connect any number of
Stages to thisWarehouse. AsFreightoriginating from it are promoted to eachStage, they will utilize a simple promotion process that:- Updates some stage-specific configuration to reference the new image revision and uses a configuration management tool like Kustomize or Helm to combine the application's "base" configuration with the updated stage-specific configuration.
- Writes the combined configuration to a Git repository.
- Triggers an associated Argo CD
Applicationto sync with the combined configuration.
The combined configuration can be written to the same Git repository that is
monitored by the Warehouse or an entirely separate repository.
If writing to the same repository, the combined configuration should be written
to a different (possibly state-specific) branch or to a specific path within
the main branch that is ignored by the Warehouse so as not to
created a "feedback loop."
This is discussed in greater details in the Storage Options section.
Parallel Pipelines
Kargo does not require that all resources within a single Project participate
in a single DAG. Multiple, disconnected DAGs can exist within a single Project
to effect completely independent workflows for different applications.
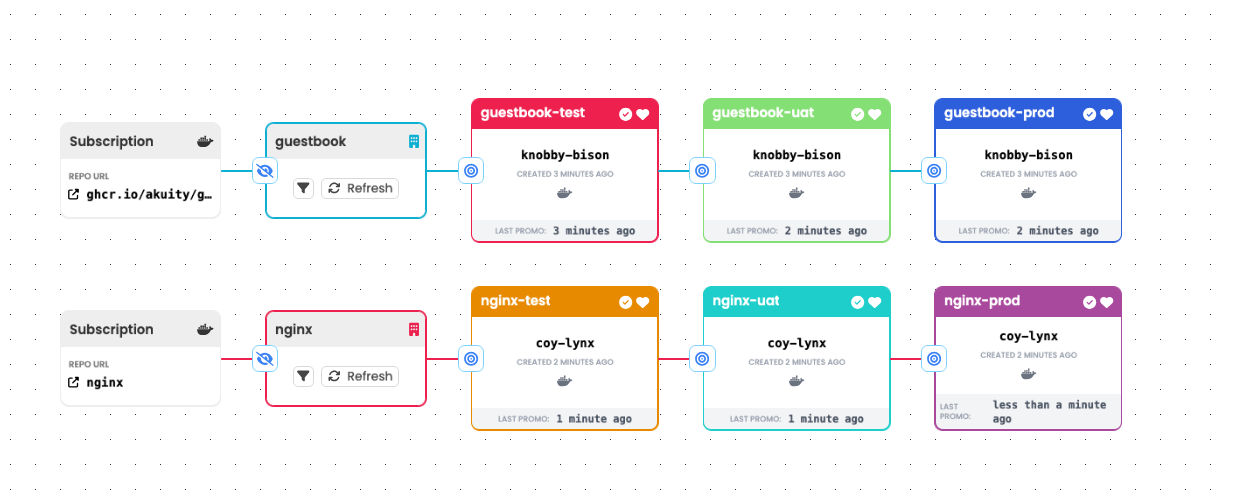
The choice to define multiple, independent pipelines within a single Project
might be made on the basis of organizational structure. If, for instance, a
single team is responsible for multiple, related microservices, it may make
sense to manage them together in a single Project.
Pre-Pipelines
A "pre-pipeline" can be used to "convert" pipelines implementing patterns such as the Common Case into a simpler pipeline such as one implementing the Config Updater pattern.
To apply this pattern, a single Stage in the "pre-pipeline" can create new
artifacts that are subscribed to by a second pipeline's Warehouse:
Grouped Services
In an ideal world, the lifecycles of all services or microservices would be completely independent of one another. That flexibility, after all, is one of the main benefits of a microservice architecture. But we don't live in an ideal world and it's not uncommon, for instance, that changes to the front end of an application cannot be promoted without also promoting corresponding updates to the back end.
Two specific features of Kargo can help to manage such scenarios:
-
Artifacts referenced by a single
Freightresource are promoted from stage to stage together as a unit. -
"Stage" can mean whatever your use case requires it to mean.
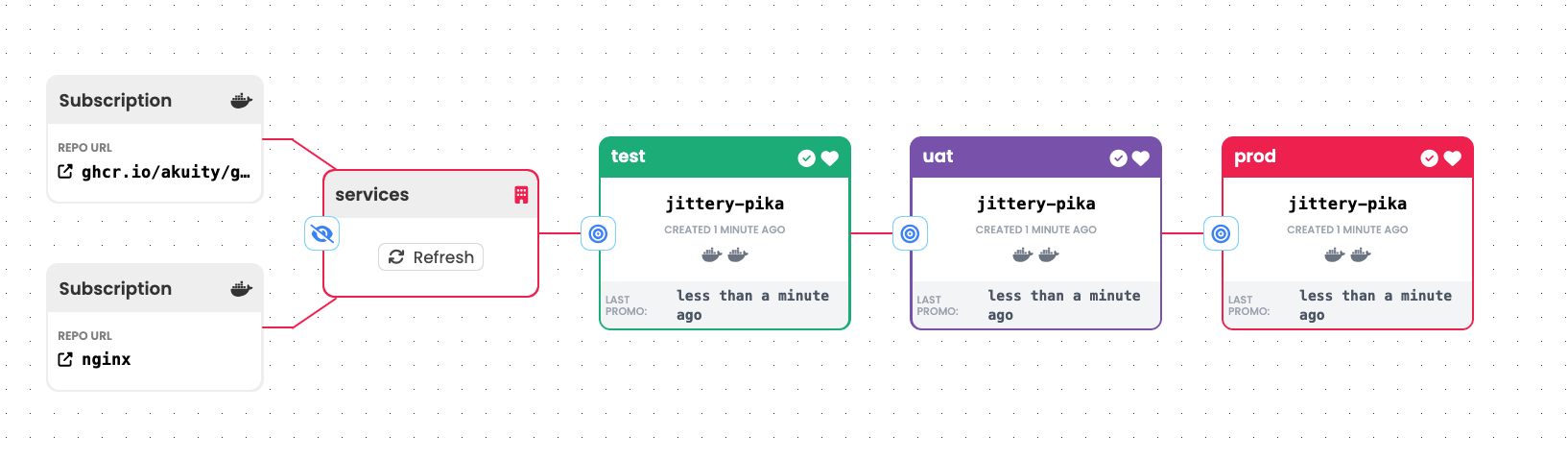
To move related artifacts through a pipeline together:
-
Create a single
Warehousethat subscribes to the repositories of all relevant artifacts. Each time it discovers a new revision of any, or all, of them theWarehousewill produce a newFreightresource referencing one revision of each. Being referenced by a singleFreightresource, these artifacts will be promoted from stage to stage together as a unit. -
Connect any number of
Stages to thisWarehouse. Here, eachStagerepresents a promotion target for multiple services. AsFreightoriginating from the oneWarehouseare promoted to eachStage, they will:- Use a suitable process to combine the artifacts into stage-specific configuration(s).
- Write the combined configurations to a Git repository.
- Trigger one or more associated Argo CD
Applicationresources to sync with the combined configurations.
A single Argo CD Application resource can manage the deployment of multiple
related services -- a fact you may sometimes wish to leverage in the case of
services that are tightly coupled.
If you find yourself creating Warehouse resources that subscribe to a large
number of repositories to create Freight resources that reference a large
number of artifacts that will all be promoted from stage to stage together as a
unit, it is advisable to stop and ask yourself if coupling the promotion of so
many artifacts was truly your intent. In many cases, users who have found
themselves doing something such as this have done so without understanding the
options that may have served their use case better.
Ordered Services
In a variation on the Grouped Services pattern, you may further require that related services be updated in a specific order. For instance, it would not be uncommon to require that changes to an application's back end be promoted prior to any changes to its front end. There are a number of ways to approach this.
-
Leverage Your GitOps Agent
Argo CD, for instance, has a feature called sync waves that can be used to control the order in which resources are synchronized.
-
Serialize
ApplicationsyncsInstead of concluding a promotion process by triggering one or more Argo CD
Applicationresources to sync all at once, a promotion process may be designed to triggerApplicationsyncs sequentially, either at the end of the process, or one at a time as other specific steps of the process are completed. -
Leverage the flexible definition of "stage"
By defining a pipeline like so, a subset of artifacts referenced by a
Freightresource can be "dropped off" at eachStage: note
noteIn this example, with alternating stages promoting a different subsets of the artifacts referenced by a
Freightresource, there are two (slightly) different promotion processes used by alternating stages.
Fanning Out / In
When assembling a promotion pipeline from many Stage resources, it is not
required that the pipeline be strictly linear.
It is plausible, for instance, that after a Freight resource has been promoted
to a "test" stage and passed some battery of tests, that it should next be
promoted to two different stages for distinct purposes. Perhaps, for instance,
it may be promoted to both a "qa" stage and a "uat" stage. In the "qa" stage,
QA engineers will try their hardest to break the application, which could be
disruptive to a product owner attempting to validate that business requirements
have been met -- if not for the product owner's own "uat" stage. This is an
example of "fanning out."
When fanning out is applied, it is also possible to promote Freight to
multiple "downstream" stages simultaneously.
"Fanning in" is the inverse of fanning out. It is a case where a single stage
can have Freight promoted to it after passing required tests in any one of
multiple "upstream" stages.
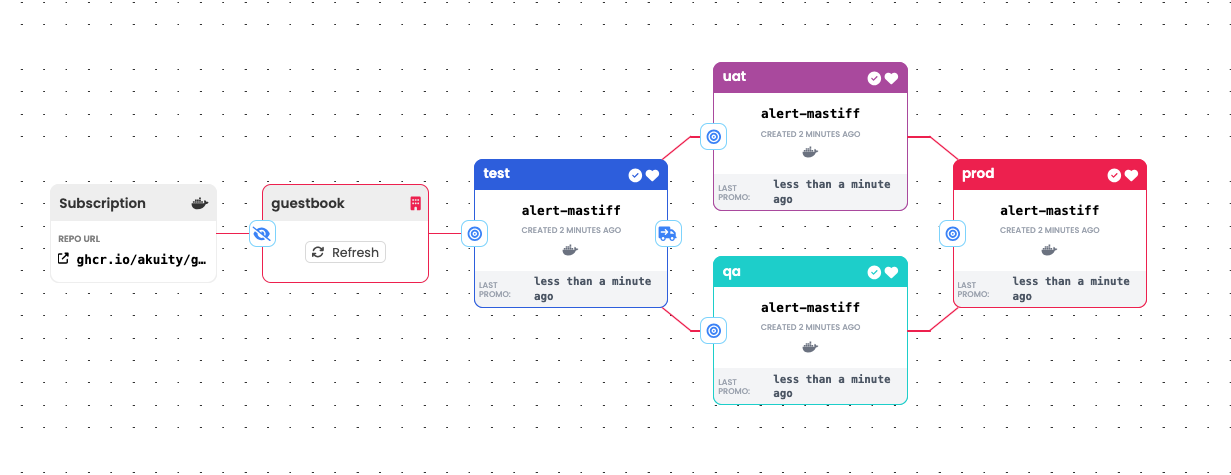
Fanning out and back in can also be an effective way to implement A/B testing.
Here, different Freight resources referencing different revisions of a
container image have been promoted into the "A" and "B" stages. When one of
these or the other has been deemed suitable for production, that one can be
promoted:
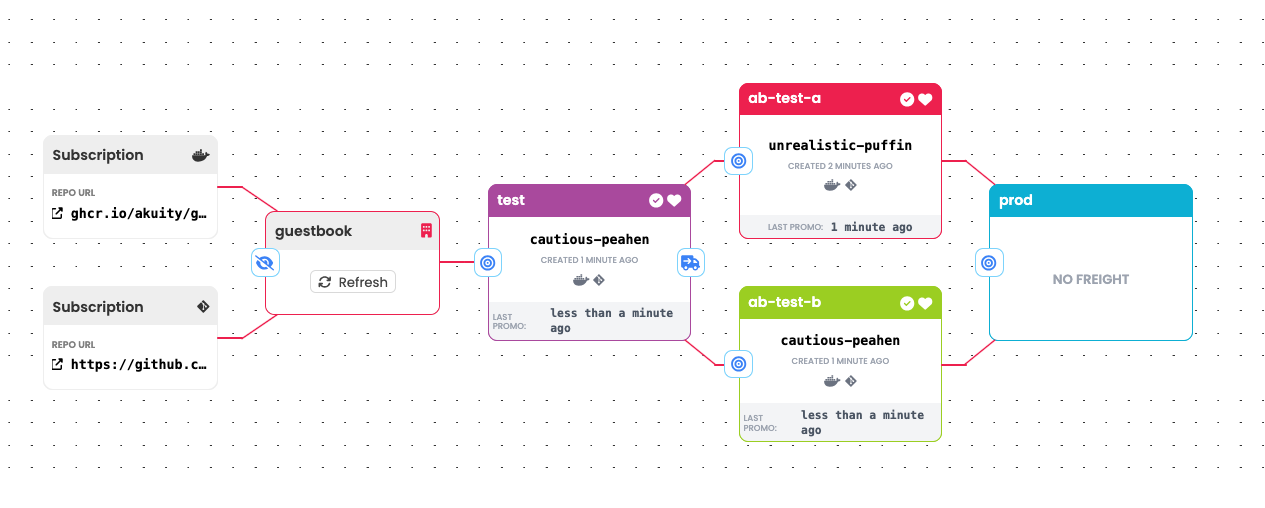
It is common for pipelines to fan in or out (or both) at Control Flow Stages.
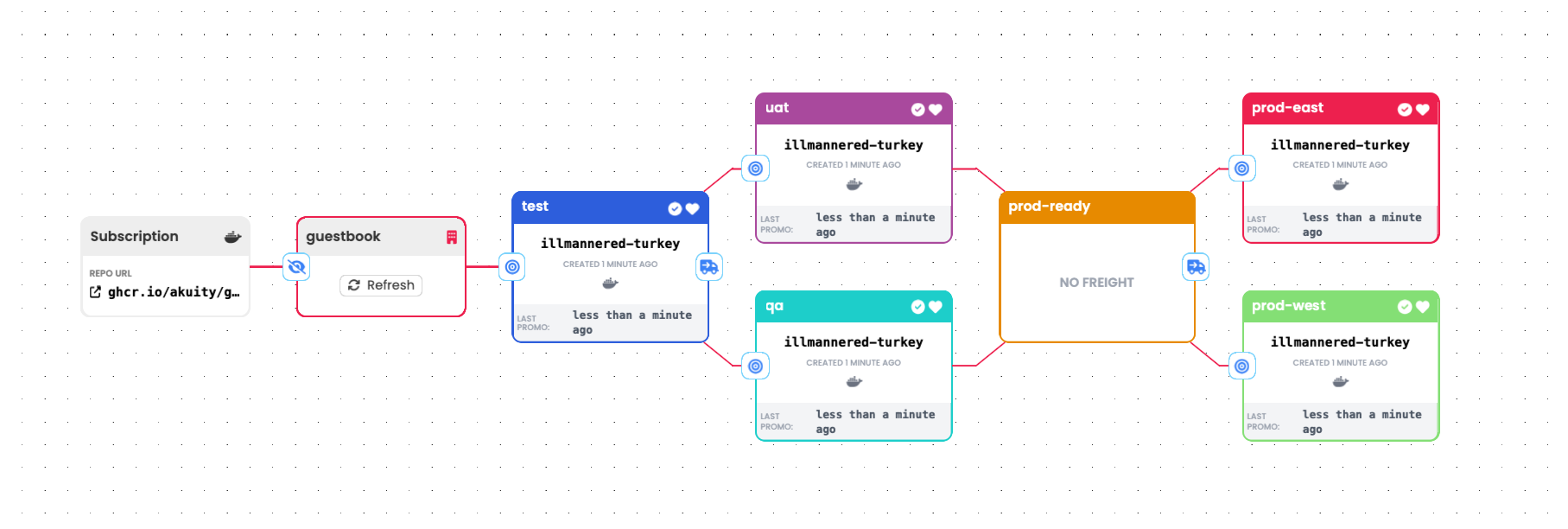
Control Flow Stages
Control flow stages are stages that define no promotion process. Their utility is only to de-clutter a pipeline (see Fanning Out / In) or to provide an additional interaction point within it.
A "tangled" pipeline:
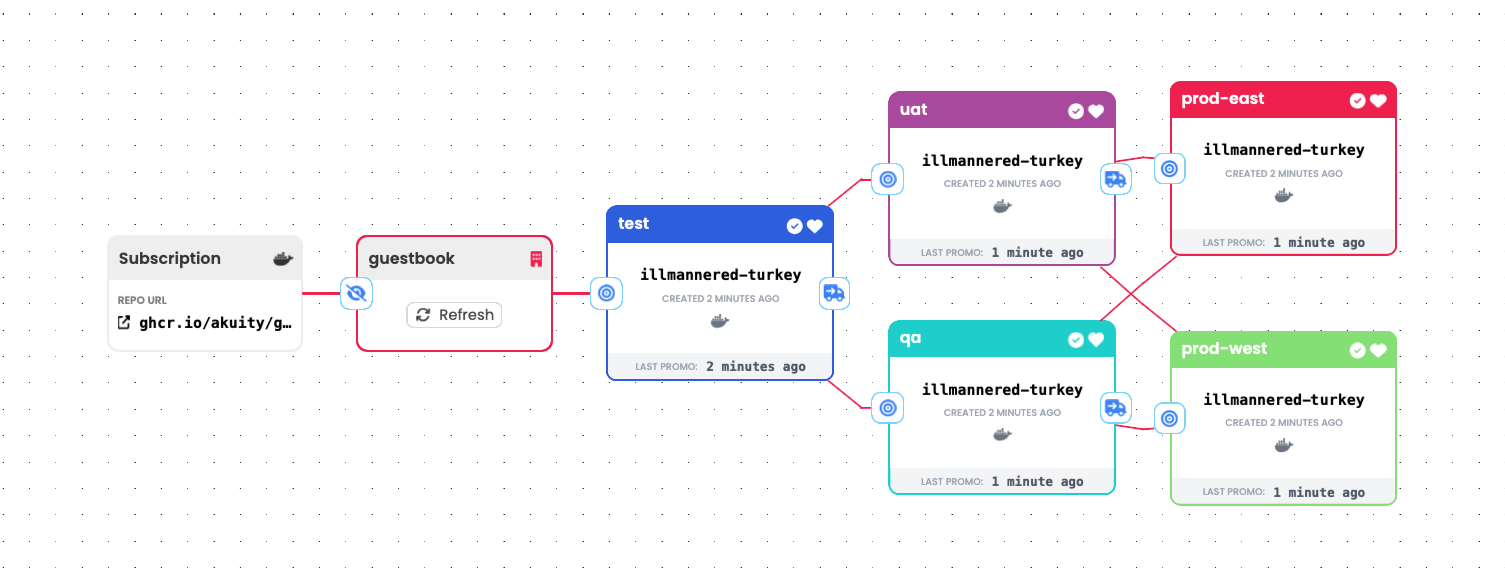
Using a control flow stage:
Multiple Warehouses
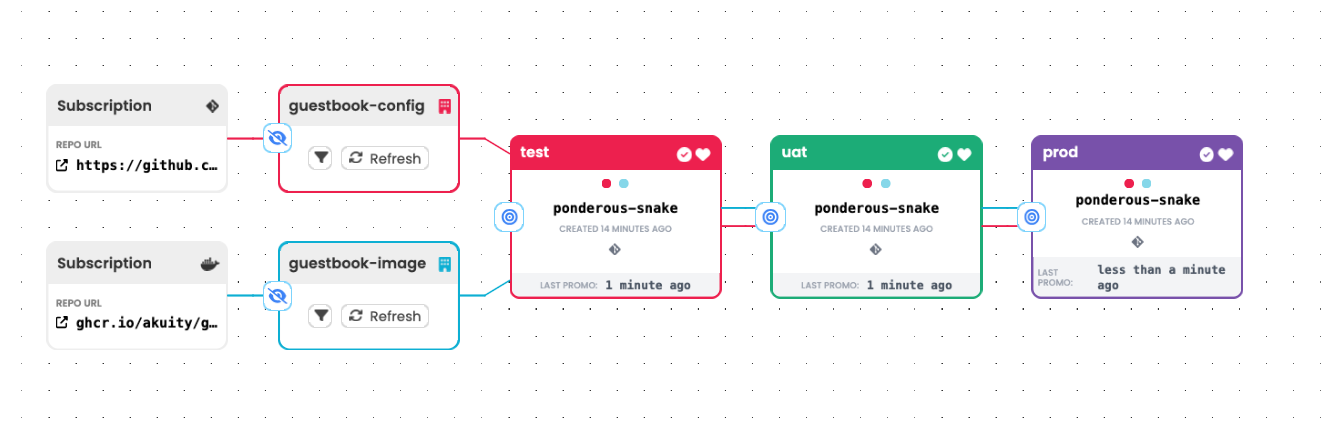
This pattern is in some ways the inverse of the
Grouped Services pattern. In the Grouped Services pattern,
we learned that a single Warehouse that subscribes to multiple repositories
produces Freight that reference multiple artifacts that will be promoted from
stage to stage together as a unit.
A corollary to this is that artifacts in different Freight resources can
be promoted from stage to stage independently of one another.
Consider a scenario wherein it is common to promote new revisions of a container
image from stage to stage, all the way to production, rapidly and many times per
day, whilst configuration changes are more rare and are promoted more slowly,
with greater deliberation. In such a case, "packaging" image revisions and
configuration changes into a single Freight resource would make it all but
impossible to promote the image revisions and configuration changes at different
cadences.
The solution to the above is to create two separate Warehouse resources, with
one subscribing to the container image repository and the other subscribing to a
Git repository containing configuration. Each Warehouse will produce Freight
resources that reference just a single revision of an artifact. Both
Warehouses can be connected to the same Stages, so that each Stage
effectively has two parallel pipelines running through it, with each of those
delivering one type of artifact or the other.
Freight Assembly
At times, when applying other patterns such as the Common Case
or Grouped Services -- any pattern that involves Freight
resources referencing multiple artifacts -- you may encounter a specific
difficulty: Sometimes there is a time delay between the discovery of a new
revision of one artifact and the discovery of a new revision of another.
To illustrate this difficulty, imagine that new versions of a container image
frequently require corresponding changes to application configuration -- for
instance, new environment variables that must be set. If a Warehouse that
watches for new revisions of the image and the configuration frequently
discovered new revisions of the image without a new revision of the
configuration, the Freight resources it produces would frequently pair new
image revisions with incompatible configuration.
One strategy for dealing with this is to configure the Warehouse to
continuously discover new revisions of artifacts, but without automatically
producing Freight resources. This configuration permits a user to use the
"Freight Assembly" feature to manually select a compatible combination of
revisions to promote.
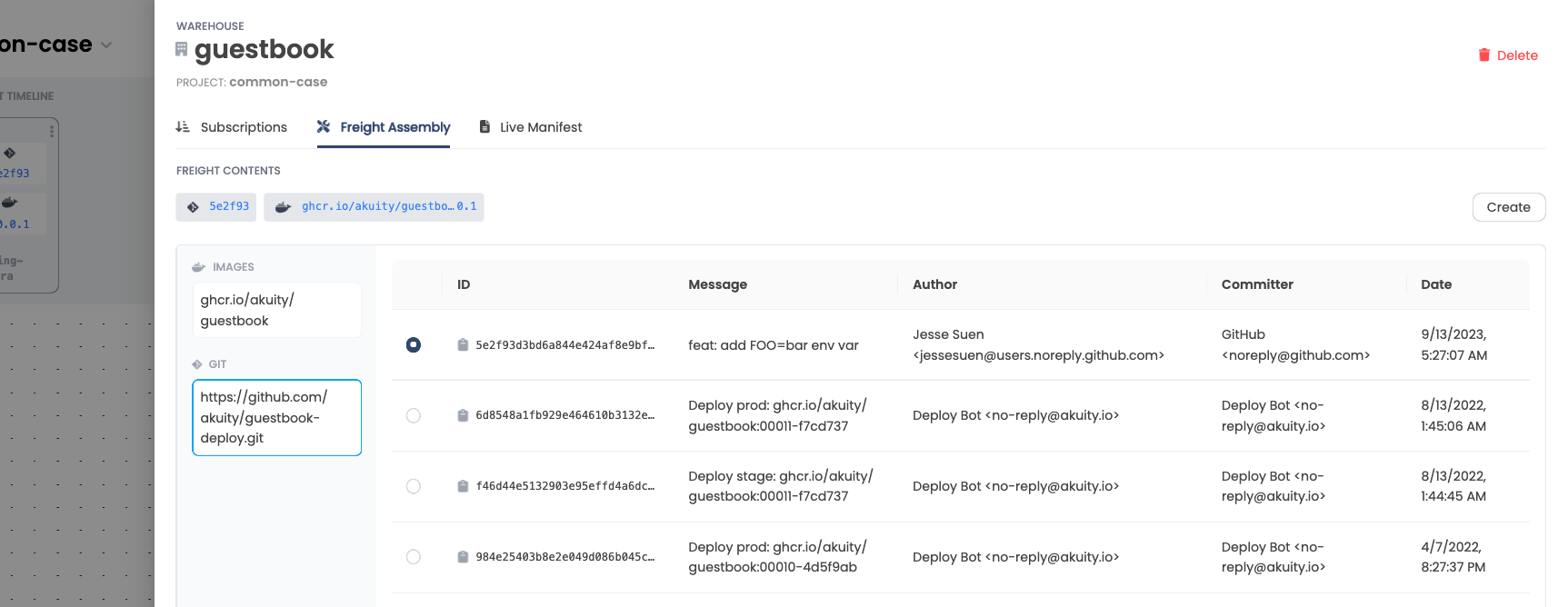
Additional features have been proposed to limit the automatic production of
Freight that may reference incompatible revisions of different artifacts,
which, in time, are likely to be implemented as well.
Mixed Promotion Modes
Promotion policies can be configured to allow or disallow new Freight
resources being promoted to each stage automatically. It is common for policies
to permit new Freight to progress from stage to stage automatically up to a
point, with promotions beyond that point, and into production, being manual.
There are less obvious uses for this feature, however.
Revisiting the problem posed in the introduction of the
Freight Assembly
pattern (incompatible artifact revisions), it is possible to leave automatic
Freight production enabled on the Warehouse, but disallow auto-promotions to
the leftmost Stage ("test," perhaps). In this way, any invalid combinations of
artifact revisions will not be immediately promoted to the "test" stage.
Instead, a user can manually select a Freight resources referencing a valid
combination of artifact revisions for promotion to that Stage.
Gatekeeper Stage
Once again touching on the problem of Freight referencing incompatible
artifact revisions, if resources permit, it is possible to introduce a
"gatekeeper" Stage at the far left side of a pipeline. This is a Stage
wherein things are allowed to fail.
With a gatekeeper Stage in place, your Warehouse can continue producing
Freight resources automatically and new Freight resources can be promoted
automatically to the gatekeeper Stage. Freight resource can also be
promoted automatically from the gatekeeper Stage to the next Stage, but
failures in the gatekeeper Stage will block incompatible combinations of
artifact revisions from progressing further.
A Freight resource referencing incompatible revisions of different artifacts
is likely to be succeeded shortly by a new Freight resource that references
compatible revisions of the artifacts, which will successfully clear the
gatekeeper Stage.
Repository Patterns
This section documents common strategies for organizing Git repositories housing application configurations. In general, the layout of any such repository must provide for the separation of common, "base" configuration applicable to all from stage-specific configuration that is unique to each.
As with all patterns presented in this document, you should not consider yourself constrained by them. They are presented here as a starting point for your own creativity.
Layout with Helm
If your Git repository contains configuration in the form of a Helm chart, it is
common that the chart's values.yaml file, which provides default options
during chart installation, will contain "base" configuration. Stage-specific
configuration can be provided by supplemental values files that amend or
override defaults found in the base values.yaml.
A typical layout for such a repository may resemble this one:
.
├── Chart.yaml
├── stages
│ ├── prod
│ │ └── values.yaml
│ ├── test
│ │ └── values.yaml
│ └── uat
│ └── values.yaml
├── templates
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ └── service.yaml
└── values.yaml
Layout with Kustomize
If you utilize Kustomize for configuration management, it is common to organize configuration with a common "base" and stage-specific overlays.
A typical layout for such a repository may resemble this one:
.
├── base
│ ├── deploy.yaml
│ ├── kustomization.yaml
│ └── service.yaml
├── charts
│ └── kargo-demo
└── stages
├── prod
│ └── kustomization.yaml
├── test
│ └── kustomization.yaml
└── uat
└── kustomization.yaml
Monorepo Layout
When working with monorepos containing configuration for multiple applications, it is common to organize configurations by application and then by stage.
A typical layout for such a monorepo storing many Helm charts may resemble this:
.
├── guestbook
│ ├── Chart.yaml
│ ├── stages
│ │ ├── prod
│ │ │ └── values.yaml
│ │ ├── test
│ │ │ └── values.yaml
│ │ └── uat
│ │ └── values.yaml
│ ├── templates
│ │ ├── _helpers.tpl
│ │ ├── deployment.yaml
│ │ └── service.yaml
│ └── values.yaml
└── portal
├── Chart.yaml
├── stages
│ ├── prod
│ │ └── values.yaml
│ ├── test
│ │ └── values.yaml
│ └── uat
│ └── values.yaml
├── templates
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ └── service.yaml
└── values.yaml
A typical layout for a monorepo storing many Kustomize configurations may resemble this:
.
├── guestbook
│ ├── base
│ │ ├── deploy.yaml
│ │ ├── kustomization.yaml
│ │ └── service.yaml
│ └── stages
│ ├── prod
│ │ └── kustomization.yaml
│ ├── test
│ │ └── kustomization.yaml
│ └── uat
│ └── kustomization.yaml
└── portal
├── base
│ ├── deploy.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── stages
├── prod
│ └── kustomization.yaml
├── test
│ └── kustomization.yaml
└── uat
└── kustomization.yaml
When storing configuration for many applications in a single repository, any
Warehouse resources that subscribe to that repository should be carefully
configured with
path filters
such that only changes to relevant configuration are detected. A guestbook
Warehouse, for instance, should be unconcerned with changes to portal
configuration.
Storage Options
Toward the conclusion of most promotion processes, output of some kind must be written to a Git repository so it can be picked up and applied by a GitOps agent such as Argo CD. There are a few viable options by which to approach this:
-
Stage-Specific Branches
This is decidedly the maintainers' preferred approach, but it is by no means required.
infoThe practice of storing stage-specific configuration in dedicated branches seems to have been unfairly maligned through misunderstanding of a certain infamous blog post, which was actually asserting that GitFlow has no place in GitOps.
Some users also object to this approach on the grounds that they don't wish to maintain a large number of branches. In fact (this is not GitFlow), it is never incumbent upon users to merge changes between branches. Thus, we encourage users to view stage-specific branches not as a maintenance burden, but simply as storage. If it helps to conceptualize it, each branch may as well be an S3 bucket.
-
Writing Back to
mainUsers who truly prefer to work with only a single branch may choose to write the output of any promotion process back to their
main(trunk) branch, however, doing so requires some deliberate care. The output of promotion processes should be written to paths within the repository that are distinct from the input to those processes.For example, the following repository layout keeps the input to promotion processes in the
srcdirectory and the output in thebuildsdirectory.warningAny
Warehouseresources that subscribe to this repository must carefully apply path filters to ensure that changes within thebuildsdirectory do not trigger the production of newFreightresources. Failure to do so may result in a "feedback loop.".
├── builds
│ ├── guestbook
│ │ ├── prod
│ │ ├── test
│ │ └── uat
│ └── portal
│ ├── prod
│ ├── test
│ └── uat
└── src
├── guestbook
│ ├── base
│ │ ├── deploy.yaml
│ │ ├── kustomization.yaml
│ │ └── service.yaml
│ └── stages
│ ├── prod
│ │ └── kustomization.yaml
│ ├── test
│ │ └── kustomization.yaml
│ └── uat
│ └── kustomization.yaml
└── portal
├── base
│ ├── deploy.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── stages
├── prod
│ └── kustomization.yaml
├── test
│ └── kustomization.yaml
└── uat
└── kustomization.yaml -
Writing to a Separate Repository
Kargo does not require that the output of promotion processes be written to the same repository that is monitored by
Warehouseresources. If it suits your use case, it is plausible to write the output of promotion processes to one or multiple branches of an entirely separate repository.
Promotion Patterns
Being mostly unopinionated, Kargo does not pre-define any specific promotion processes. Instead, it provides a number of fine-grained Promotion Steps that can be combined to implement a user-defined promotion process.
This section documents a "typical" promotion process as well as a few common techniques.
Support for custom / third-party promotion steps is coming in a future release.
The Common Case
Details vary, but a common promotion process might look something like this:
-
Clone a Git repository containing the application's configuration, possibly checking out multiple commits or branches.
-
Perform small edits on specific files. This might, for instance, involve updating a
values.yamlfile in a Helm chart to reference a new revision of a container image. -
Combining the application's "base" configuration with stage-specific configuration. This could be as simple as copying relevant configuration to some other location or could involve a configuration management tool like Kustomize or Helm as described in the Rendered Configs pattern below.
-
Write the updated and combined configuration to a Git repository using any option laid out in the Storage Options section.
-
Trigger an associated Argo CD
Applicationresource to sync with the newly promoted configuration.
Rendered Configs
This common pattern is easily combined with most others and, in fact, we've alluded to it in some of the other patterns:
Uses a configuration management tool like Kustomize or Helm to combine the application's "base" configuration with stage-specific configuration.
To make a finer point of this, "rendering" configs means using (Kargo's
equivalent of) commands like helm template or kustomize build to generate
Kubernetes manifests that are plain YAML and require no further processing to
be applied to a cluster.
While Kargo does not require that you do this, it is a technique we highly
recommend chiefly because diffing plain YAML (whist reviewing a PR, perhaps)
promotes a comprehensive understanding of the changes to be applied. By
contrast, diffing changes to a Helm values.yaml file or a Kustomize overlay
both require knowledge of those tools and some degree of mental gymnastics to
reason over the changes that will be applied after the GitOps agent has
performed the rendering.
Pre-rendering configuration in this manner can also boost the performance of your GitOps agent, which will be relieved of any responsibility for executing configuration management tools.
Pseudo-GitOps
This pattern is intentionally presented last because it's not real GitOps in that desired state is not declared (or not entirely declared) in a Git repository.
Kargo does permit user-defined promotion processes to directly mutate the state
of Argo CD Application resources. This can be used, for instance, to update
Helm-specific or Kustomize-specific attributes of an Application resource. It
can also be used to update the source.targetRevision field to effectively
change the Git commit or Helm chart version to which the Application syncs.
Kargo implements these capabilities mainly to reduce the overhead of simply experimenting with Kargo, but we strongly recommend against applying this pattern in a production setting.